
SLAT: Recorte Adaptativo de Segmentos en Razonamiento CoT
SLAT: recorte adaptativo por segmentos reduce un 50% la longitud del razonamiento CoT sin perder precisión.
SLAT: recorte adaptativo por segmentos reduce un 50% la longitud del razonamiento CoT sin perder precisión.
Aprende sobre Feedback Distillation, un método que mejora la demostración de teoremas en Lean4 superando al GRPO. Incrementa diversidad y eficiencia en el entrenamiento de modelos de razonamiento.

Aprende cómo MVL usa suavizado espacial para estimación de valor estable en RL offline, mejorando navegación y manipulación robótica.
Descubre cómo H-EARS mejora eficiencia energética y estabilidad en RL con recompensas híbridas guiadas por física. Resultados en benchmarks y simulaciones.

La amplificación de errores temporales limita la conversión de ANN a SNN en control continuo. Conoce CRPI, una solución ligera que suprime estos errores y recupera el rendimiento.

Descubre un algoritmo Actor-Critic que converge globalmente en juegos multiagente incorporando aversión al riesgo. Garantías de muestra finita y superioridad sobre métodos neutrales al riesgo.

Descubre IAPO: asigna ventajas a cada token según información mutua. Reduce razonamiento hasta 36% sin perder precisión. Optimiza tus modelos de lenguaje.

Descubre cómo el aprendizaje por refuerzo con información física (Pi-GCRL) maneja dinámicas de contacto híbridas en manipulación robótica. ¡Entra!
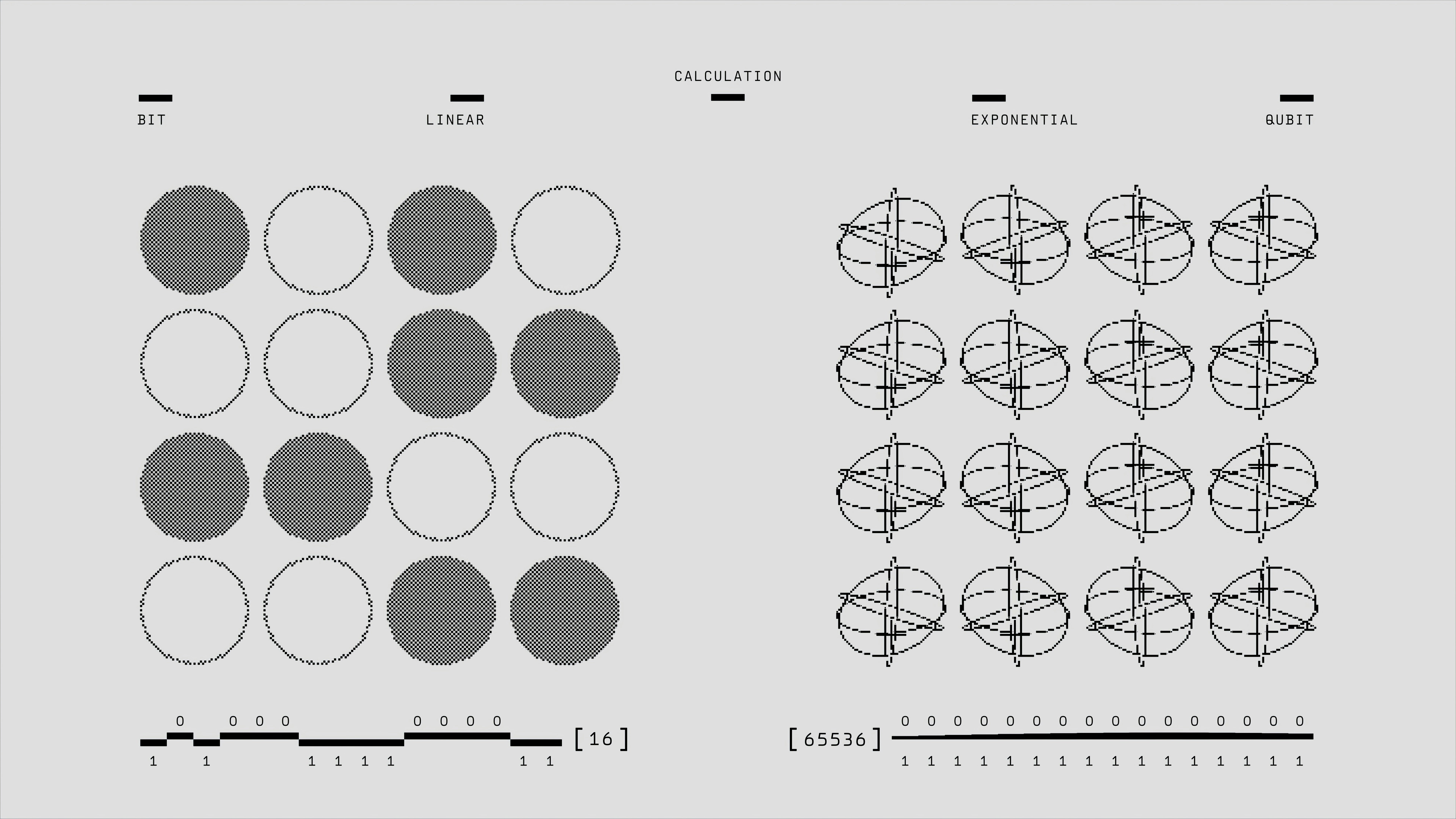
Descubre cómo SaEI mejora el razonamiento visual en modelos de lenguaje-visión mediante intervención adversarial de entropía, aumentando la exploración y diversidad de respuestas en RL.

Descubre cómo un nuevo paradigma entrena dos modelos de lenguaje como atacante y defensor en un juego no cooperativo, mejorando seguridad y utilidad. Resultados sorprendentes.

MulFeRL mejora el aprendizaje por refuerzo usando retroalimentación verbal en múltiples turnos para superar recompensas escalares y potenciar el razonamiento.

Descubre ToolSelf, un paradigma que permite a agentes de IA reconfigurarse dinámicamente durante la ejecución, mejorando el rendimiento sin intervención manual.

Descubre cómo el auto-bloqueo de información afecta el razonamiento activo de agentes LLM y cómo el método AREW lo mitiga, logrando mejoras de hasta 60 puntos.

Descubre MAVEN-T, un innovador marco de destilación reforzada que logra predicción de trayectorias multiagente en tiempo real con 6.2x menos parámetros y 3.7x más velocidad en Jetson Orin.

Descubre TrafficClaw, un agente de IA basado en LLM que optimiza el control de tráfico urbano en entornos físicos unificados con aprendizaje por refuerzo.

Descubre MARFT, un nuevo marco de ajuste fino por refuerzo multi-agente para optimizar sistemas de agentes LLM. Mejora colaboración y razonamiento.

Descubre cómo RGPD, con redes gráficas y pesos dinámicos, mejora un 12% la precisión en RUL y SoH en motores, rodamientos y baterías.

Descubre cómo TuneAgent utiliza aprendizaje por refuerzo para ajustar el kernel de Linux, mejorando el rendimiento hasta un 5.6% de forma autónoma y precisa.

Los benchmarks actuales no revelan las fallas de los métodos de RL en LLMs. Descubre el OPG y principios para evaluar la generalización.

En TRMs, el razonamiento latente actúa como operador de mejora de política. Con RL y difusión, reducimos 18x los pasos.